 Success-Plan Services
Success-Plan Services Neil Puthuff
Neil Puthuff
As real-time distributed systems become increasingly complex, the factors that affect the performance of the systems also become increasingly complex to model and test. Extrapolating results from simplistic performance tests or non-representative deployments has to be done carefully. Before relying on the results of any benchmark testing, you want to ensure that the test conditions are applicable to your application architecture and design. As an example, ROS 2 systems are almost always built using multiple processes which allow the system to be lean, modular and maintainable. Multiple processes should therefore be reflected in its test conditions.
Without these real-world considerations, your benchmark performance test is likely to yield misleading results. More accurate results come through representative, real-world setups that include scalability requirements, large data sets and a many-to-many topology. To get an accurate picture of performance, you need to check what the benchmarks are truly informing and whether they are applicable to your system design [See Benchmarking Best Practices for criteria to consider].
At RTI, we understand that top performance is critical to every project. Connext® DDS has been designed to provide throughput that both scales with payload size and delivers very low latency. But rather than talk about it, we wanted to show you how Connext performs in real-world conditions. This blog will walk you through recent tests on open-source ROS 2 benchmarks. It compares Connext DDS performance against other DDS implementations using some public benchmarks, such as those used on the Open Robotics ROS 2 nightly CI build farm. In particular, it measures the areas of performance that are critical: latency, throughput and reliability (packet loss).
Let’s get started. You can also view the video of this testing as described below.
1. Integrated Benchmark Applications
The most-common applications for testing ROS 2 Middleware Wrapper (RMW) performance have a common origin in the Apex performance_test application. This includes forks and variants from iRobot, Barkhausen Institut, and the performance_test used on the ROS 2 nightly build farm.
For the first part of this test, we’ll use the ROS 2 build farm test, to replicate the results seen on the ROS 2 nightly build site. This will be run on a Dell G7 notebook PC under Ubuntu 20.04.
Getting and building the application is straightforward and should happen without errors. The test application can be run directly; there is no need to call “ros2 run (package name) (app name)”. It takes command-line arguments to control the test and produces a sequential log file of the results. Tests are run individually for every data type, at different publication rates, with every ROS RMW variant, resulting in a large number of tests and log files. To help automate this process, we’ve created a shell script to step through each test variant, and a Python script to help condense the hundreds of log files into a single report.
The results we obtain using this test are similar to those posted on the ROS 2 nightly build site. We have conducted this test for the purpose of direct apples-to-apples comparison, but it's important to note the following:
- The ROS 2 nightly performance is using an older (and now obsolete) “rmw_connext_cpp.” RMW. This was the first RMW-DDS layer developed and has known performance issues caused by unnecessary memory allocations and copies done in the RMW layer itself. This has now been fixed in two new RMW called “rmw_connextdds” and “rmw_connextddsmicro” both contributed by RTI, which are being included in the ROS 2 nightly builds “soon”™ (more about this below in our test results).
- The nightly-build test runs everything in a single-process; however, most ROS 2 systems are composed of multiple processes.
So why does this matter? After all, speed is speed, right?
Quite simply, communication between application threads in a single process doesn’t require middleware. Threads can exchange data and data-references directly over the common memory space provided by the process. Therefore performance test results run using a single process are not representative of what realistic systems will see.
We talk more about this below, but next, let’s try a benchmark test that looks more like a ROS 2 system that we’ve seen in actual production environments.
2. Testing a More Realistic ROS 2 System
As a proof of concept, I put together a set of (3) ROS 2 applications, written in the same style as the ROS 2 tutorial examples for “Writing a simple publisher and subscriber (C++)”. In other words, this test is as “ROS 2” as it can possibly be.
The test is composed of 3 types of ROS 2 nodes which run in separate processes:
- SOURCE node, which publishes a message with an embedded timestamp.
- WORK node (optional), which subscribes to a message, adds its own timestamp, then re-publishes it on a separate topic.
- SINK node, which subscribes to a message, timestamps it, then calculates the latencies seen at each step and accumulates statistics and histogram data, writing the results to files.
Like the integrated tests, this test accepts arguments for different sizes, pub rates, RMW types, etc. We have just made them small, focused tests that run in separate ROS 2 processes to mimic a deployed ROS 2 system.
This test is designed to support many different system configurations, by arranging as many SOURCE, WORK, and SINK nodes as needed: 1:1, 1:N, N:1, N:N, long chains in series, parallel, etc. – whatever matches the needs of your system. For this test, we’ll be using a simple SOURCE–>SINK arrangement (without any WORK notes) to match the primary configuration of the nightly ROS 2 build test.
The test application is built the same way as any other ROS 2 application: download to a directory, run colcon build, then source the result and run the test. The test offers a wide variety of command-line options. So to make testing easier, a set of ROS 2 launch files are included for different system configurations, and shell scripts are also included to automate the testing.
For example, to run a quick test of all RMW types across a wide range of data sizes that completes in about 3 minutes, run:
./scripts/run_quick_a.sh
This is far from a comprehensive benchmark test, but it is more closely aligned with real-world ROS 2 systems and already produces some interesting, non-intuitive results.
Comparing the Results
One of the more noticeable results is the vast improvement in performance from the two new RMWs for RTI Connext:
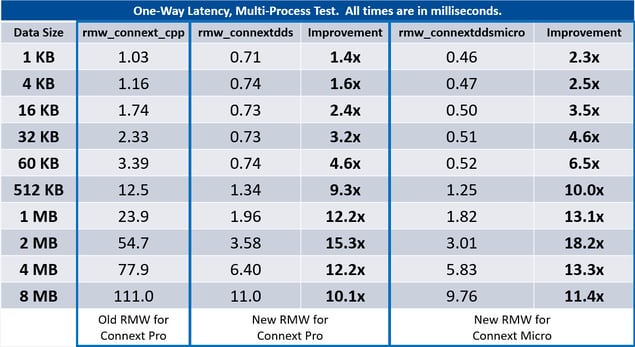
Connext DDS Micro scores the best multi-process results across all data sizes and Connext DDS Professional brings next-best multi-process performance with large data sample sizes.
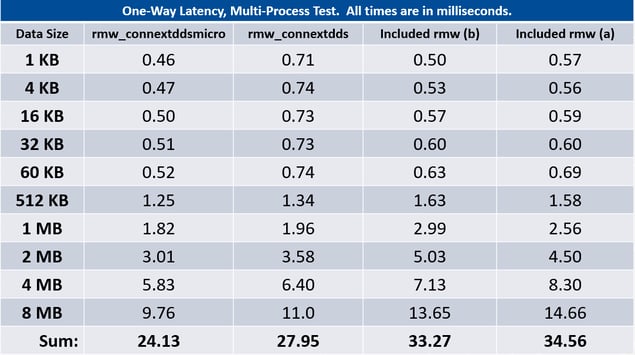
The second observation is the poor correlation of multi-process and single-process test results for some RMW implementations, but not for Connext:
.jpg?width=690&name=RMW%20A%20(blog).jpg)
%20Image%20%232.jpg?width=635&name=RMW%20B%20(blog)%20Image%20%232.jpg)
.jpg?width=690&name=RMW%20RTI%20-%20%233%20(blog).jpg)
Some RMWs that exhibit good performance in single-process results are actually the worst performers when running the same test in multiple processes.
Why is that? The reason is that some RMWs (or middleware implementations) are using an “in-process” trick that is activated if the destination of a data packet is to be in the same process as the source. If so, a shortcut is taken that bypasses the DDS serialization, protocol and transport stacks to make a same-process delivery. This can improve performance, but only if your ROS 2 system will be similarly composed of a single process. This is very unusual for ROS 2, and it comes at the cost of compromising modularity (i.e., introducing some of the coupling between Publishers and Subscribers).
Local delivery in a single process application has its uses, but most of the time it will not be representative of a deployed system. And if you were architecting that system that depended on deploying multiple ROS nodes in the same process and needed to squeeze that extra bit of large-data performance, you could also get it by sending a data-pointer rather than the data itself.
Incidentally, Connext DDS also supports a Zero Copy mode that can get the increased performance when sending large data inside a Process or over shared memory. Moreover, the Zero Copy approach used by Connext does not "bypass" the serialization and protocol and therefore does not cause the undesirable “coupling” side-effects. However, the Connext Zero Copy utilizes a specialized API that cannot be mapped to the ROS RMW API. You can explore the benefits of the Zero Copy feature as well as more extensive performance scenarios using rtiperftest (the RTI performance benchmarking tool), and the results of a previous RTI blog.
And that leads us to where we started this conversation: Benchmarks can be valuable if they are conducted under realistic conditions to your use case. We’d love to hear if you get the same results from your own benchmarks testing. Let me know if RTI can help you get started.
About the author
 Neil Puthuff is a Senior Software Integration Engineer for Real-Time Innovations with a focus on Robotics and Automotive Systems, and RTI team lead for the Indy Autonomous Challenge. Versed in hardware as well as software, he created the processor probes and replay debugging products at Green Hills Software before joining RTI. Neil is a named inventor on more than a dozen US patents.
Neil Puthuff is a Senior Software Integration Engineer for Real-Time Innovations with a focus on Robotics and Automotive Systems, and RTI team lead for the Indy Autonomous Challenge. Versed in hardware as well as software, he created the processor probes and replay debugging products at Green Hills Software before joining RTI. Neil is a named inventor on more than a dozen US patents.