Success-Plan Services
Success-Plan Services
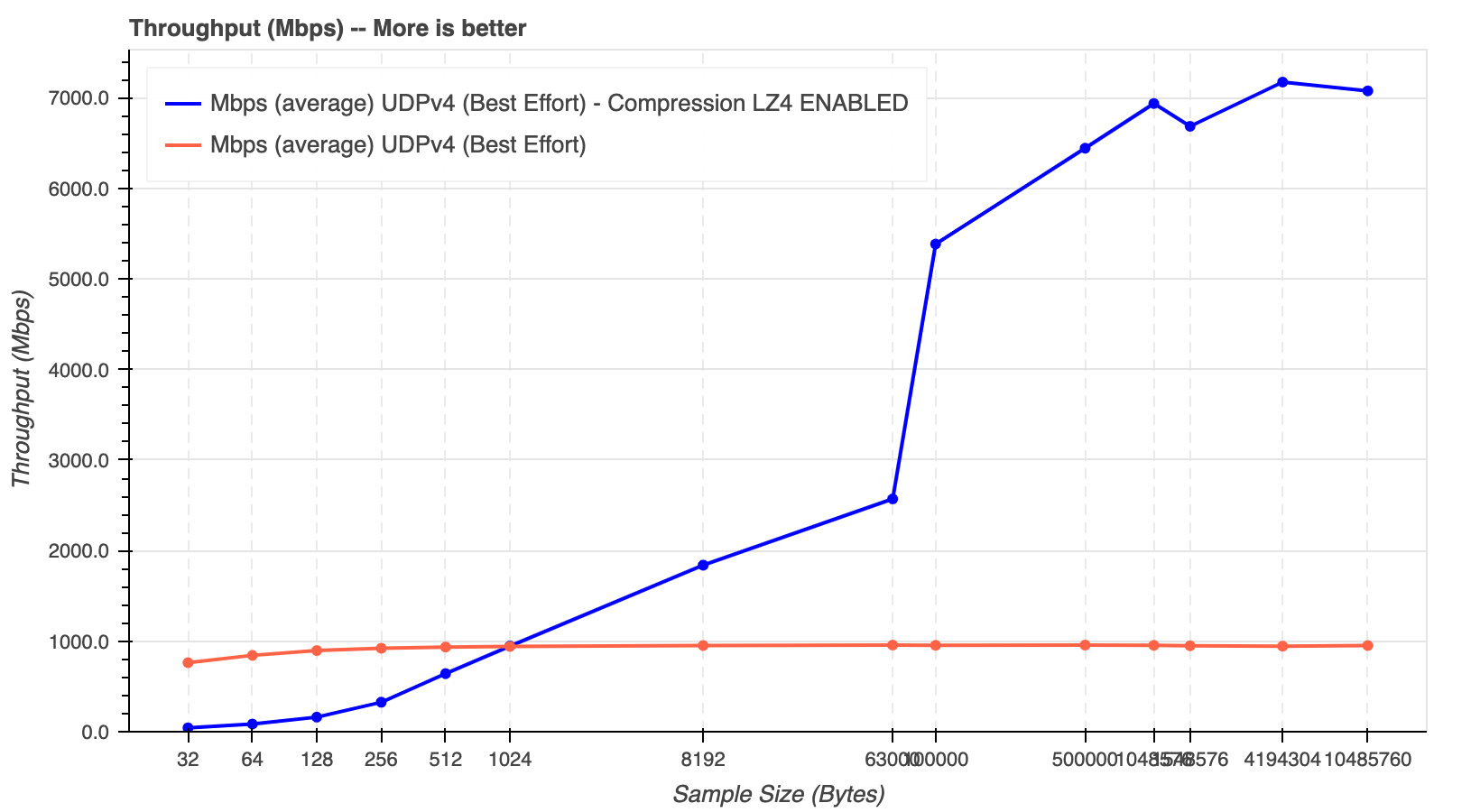
High Throughput
Approaching the theoretical bandwidth of Gigabit Ethernet, using modest CPUs
|
RTI Connext provides a significant performance advantage over most other messaging and integration middleware on every supported platform.

The PerfTest benchmarking tool is completely free, along with documentation and a video tutorial.
To run these benchmarks on your own hardware, please download or contact your local RTI representative:
.png?width=803&height=441&name=bokeh_plot%20(1).png)
%20copy.png?width=803&height=441&name=bokeh_plot%20(1)%20copy.png)