 Success-Plan Services
Success-Plan Services Neil Puthuff
Neil Puthuff

Slashing latency by 98% will help win the race. Here’s how.
When it comes to competitive automobile racing, every detail counts. Aerodynamics, tire composition, fuel/air chemistry, and even human physiology are scrutinized and optimized in the hope of gaining even the slightest competitive edge. Like their passenger-car counterparts, modern racing engines and powertrains are increasingly controlled by software, with a range of performance settings to match the conditions on race day. When it’s time to start measuring high performance in microseconds, software wins races.
At RTI, we know some things about automotive performance optimization. That’s why we became a sponsor of the Indy Autonomous Challenge (IAC), a $1.5 million prize competition among universities to create the software and compete in the world’s first autonomous head-to-head race around the famed Indianapolis Motor Speedway on October 23, 2021. The IAC takes the concept of “software wins races” to an unprecedented new level by having no human driver in the vehicle: It’s entirely driven by software.
Like every other aspect of competitive racing, the self-driving software is being tuned and optimized to run as quickly and efficiently as possible to gain that competitive advantage, because every microsecond counts. In this environment, RTI Connext® DDS is a perfect fit. In this blog post, I’ll share some specific strategies that can be taken with Connext to optimize performance in a ROS 2 system by slashing inter-process communication (IPC) latency.
The race car itself – a modified Dallara IL-15 – will be delivered to the university teams with substantial processing power and an array of sensors. The all-important software will include a pre-loaded implementation of ROS 2 and the Autoware.auto autonomous driving stack. This uniform configuration places all of the university teams on a level playing field and at an identical starting point. And then the fun begins as the teams can customize and fine tune by choosing to use any software. It’s up to their own ingenuity and attention to detail to create the software combination that will win the race.
This is where Connext has already been helping. Its capability for real-time data connectivity is ideal for making the most of every microsecond in the vehicle control system. And that performance really adds up for driverless racing cars racing side-by-side at speeds of up to 200 mph. In this race, accelerating inter-process communication speed for huge volumes of LIDAR and sensor data is vital.
ROS 2: How the Default Framework Addresses High Performance
The default framework (ROS 2) is built on top of the Data Distribution ServiceTM (DDS) standard. This is a good starting point for performance IPC latencies on the order of milliseconds down to a few hundred microseconds when using any of the most popular RMW (ROS Middleware) implementations under ROS 2:
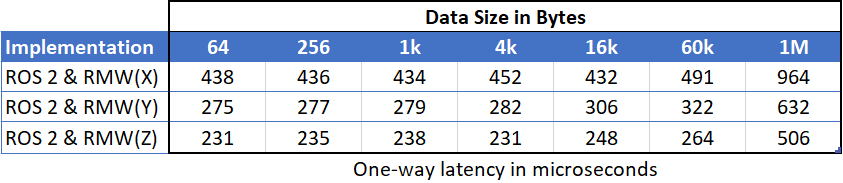
Figure 1: One-way latency for three different ROS 2 RMW implementations.
All of these RMWs are fast… but this is competitive racing. We can do better.
How Connext Addresses High Performance
Analyzing the cause of the latency in Figure 1 reveals that a good portion of the time is spent in ROS 2 itself. The good news is that because ROS 2 uses DDS for all communications, we can simply bypass the latency-inducing ROS 2 stack for our critical paths, and implement these applications directly in Connext DDS. There are many similarities to the APIs of ROS 2 and Connext DDS – after all, ROS 2 is built on DDS, so they both implement a publish/subscribe framework centered on data. This makes it relatively easy to port the ROS 2 applications to Connext DDS, aided by the ROS 2 data type code in IDL, which is available on the RTI GitHub site and covered in a recent RTI Blog article.
An example of the code changes should include replacing the initialization code that creates the DDS participant, publishers and subscribers. In brief, this should replace the ROS 2 code:

with the equivalent Connext code:

And should replace the publish/subscribe calls in ROS 2:

with their equivalents in Connext:
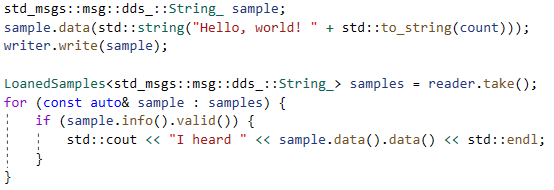
There are several notable things in these code changes:
- There is a close similarity between the ROS 2 API and the Connext API. Developers familiar with ROS 2 should feel very comfortable using the Connext API.
- The Connext API is used inside ROS 2, so there’s no new code being introduced here. By calling the Connext API directly, your code effectively bypasses the ROS 2 API stack, and its inherent latency.
- The Connext examples above are shown using the same data types as in ROS 2. This is to provide for interoperability with ROS 2 applications and tools.
The improvement is dramatic: For small data packets, more than 90% of the latency has been eliminated by this change. Large packets have also gotten a substantial reduction in latency:
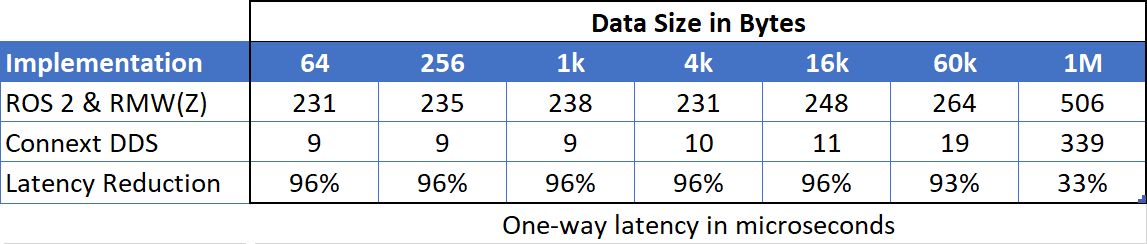
Table 2: One-way latency: ROS 2 vs Connext DDS (native implementation).
This incredible performance leap is impressive, but is this enough to win races? Perhaps. Yet racing at this level requires a relentless pursuit of performance. Let’s see if we can also improve the performance of the larger data packets. Since we’ve now implemented our critical-path applications directly in Connext DDS, we can take full advantage of its complete feature set to custom-tune our data performance.
FlatData
First, we’ll try using RTI FlatData – a novel encoding scheme that sends and receives the data packets as they appear in memory, thereby avoiding several memory copy operations. RTI FlatData reduces latency and works with shared memory or IP-based transports. Implementation takes only a few extra lines of code, and provides another big reduction in latency for large packet sizes:
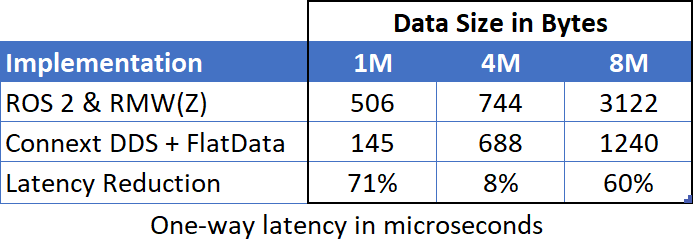
Table 3: One-way latency: ROS 2 vs Connext FlatData (native implementation).
Wow! This small change removed another big chunk of the latency of large packets that we’d seen with ROS 2.
These improvements can help separate the leaders from those in the back. But Connext has still more ways to improve system performance.
Zero Copy
For critical applications that are all running on the same computer platform and can use shared memory, we can use RTI Connext Zero Copy, an optimization wherein the data itself is not copied from sender to recipient – only a pointer to the data is sent. Once again, this requires only a small modification to our code, but produces an astonishing reduction in latency for large data packets – up to a 98% latency reduction.
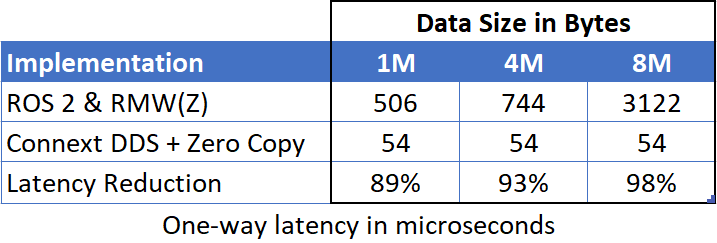
Table 4: One-way latency: ROS 2 vs Connext Zero Copy (native implementation).
The end result is that our previous minimum latency under ROS 2 for large data packets has been reduced to a small, constant value, regardless of packet size.
Summary
For the competitive race teams, moving the critical applications from ROS 2 to Connext DDS proves that fine tuning can win races. They can select the best features of Connext to shape the data traffic to their needs, typically resulting in at least 10x faster communications with data packets of any size:

Table 5: One-way latency: ROS 2 vs Connext DDS (native implementation).
Equally important, this approach enables the teams to maintain compatibility with ROS 2. By using the ROS 2 standard data types and compatible topic names, applications implemented directly in Connext can be freely intermixed with ROS 2 applications. Interoperability is assured by the OMG® DDS standard. To the ROS 2 system, these applications look identical to ROS 2 applications. They’re just a lot faster.
Regardless of whether you are racing the clock around the track or racing to meet your production deadlines, using Connext DDS in this way provides ROS 2 developers with a powerful new method of accelerating their system performance, far beyond the capabilities of ROS 2. It’s a winning strategy for any system that requires peak performance.
Resources:
ROS Data Types in IDL: https://github.com/rticommunity/ros-data-types
RTI Blog article on the above data types: https://www.rti.com/blog/ros-2-and-dds-interoperability-drives-next-generation-robotics
RTI code examples (including ZeroCopy, FlatData).
C++11 API examples: https://community.rti.com/kb/modern-c-api-code-examples
Connext features: https://github.com/rticommunity/rticonnextdds-examples
Performance tests:
RTI Perftest: https://github.com/rticommunity/rtiperftest
RTI Performance Test Results: https://www.rti.com/products/benchmarks
ApexAI Performance Test: https://gitlab.com/ApexAI/performance_test
Tests for this article were performed with RTI Perftest and ApexAI performance test using:
Dell G7 15 7590: Intel Core i7-9750H, 16GB DDR4-2666MHz, Ubuntu 20.04 64 bit.
ApexAI ROS 2 RMW latency tests were run in a single process.
RTI Perftest latency tests were run using 2 processes (1pub, 1sub).
About the Author
 Neil Puthuff is a Senior Software Integration Engineer for Real-Time Innovations with a focus on Robotics and Automotive Systems, and RTI team lead for the Indy Autonomous Challenge. Versed in hardware as well as software, he created the processor probes and replay debugging products at Green Hills Software before joining RTI. Neil is a named inventor on more than a dozen US patents.
Neil Puthuff is a Senior Software Integration Engineer for Real-Time Innovations with a focus on Robotics and Automotive Systems, and RTI team lead for the Indy Autonomous Challenge. Versed in hardware as well as software, he created the processor probes and replay debugging products at Green Hills Software before joining RTI. Neil is a named inventor on more than a dozen US patents.