 Success-Plan Services
Success-Plan Services Rajive Joshi
Rajive Joshi

Physical AI is often framed as a model lifecycle: train in the cloud, deploy to the edge, then improve the model over time.
That framing misses the harder systems problem.
Physical AI is not just software running inference near a sensor. It is a closed operational loop that spans machines, networks, operators, cloud components, and repeated model updates. Vehicles, robots, medical devices, and industrial systems must sense the world, act in real time, coordinate with other sub-systems, and keep operating under degraded connectivity. When they fail, the consequence is not a slow page load. It is a stalled workflow, a broken production cell, or a safety incident.
That changes the architecture question. The core problem is not only where inference runs. It is how data moves through the full loop: from sensing and control to live operations, to cloud analysis, simulation and model improvement, and back into deployment. In that loop, data is not just output from compute. It is part of the compute architecture itself.
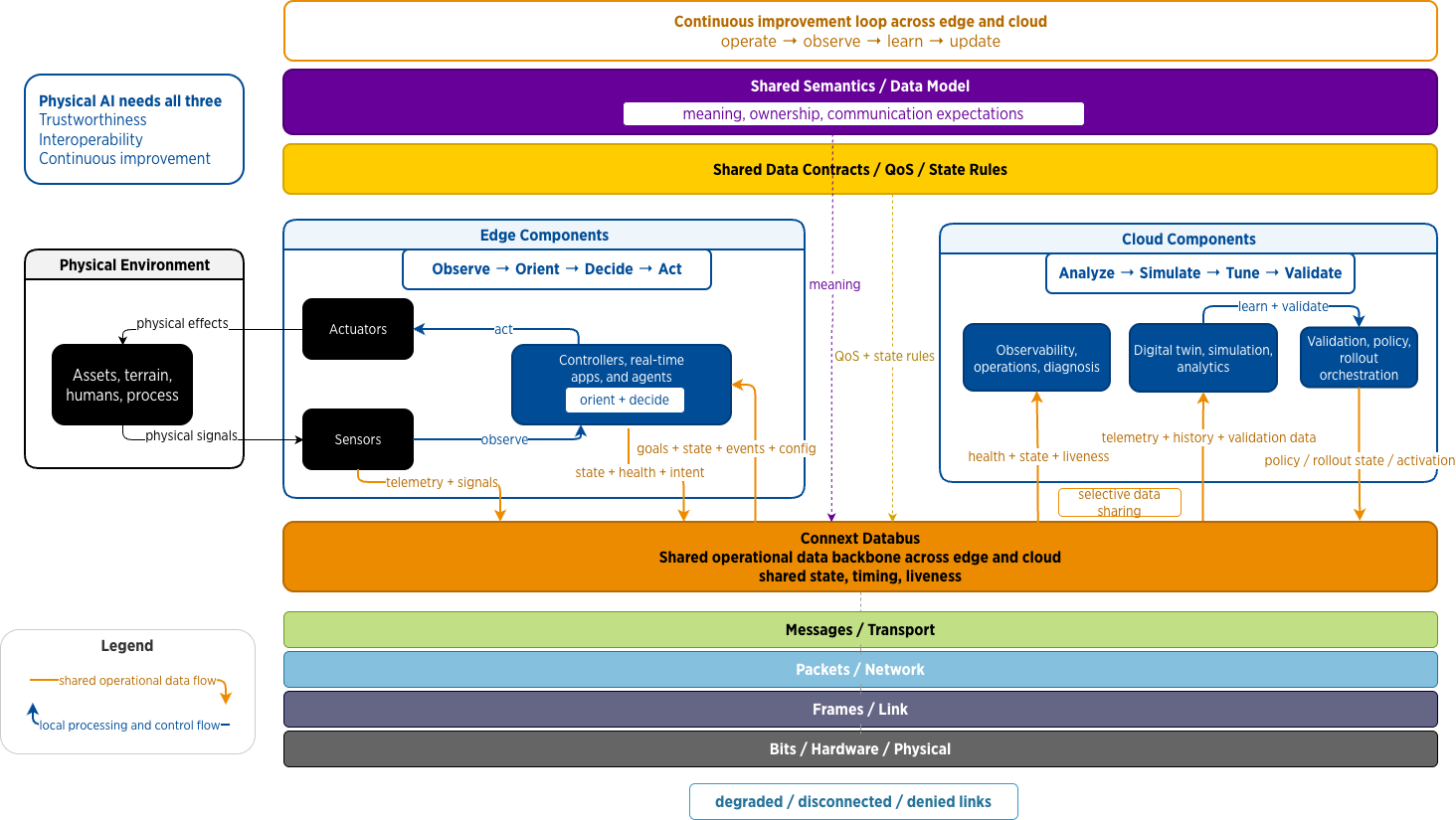
Figure 1: Physical AI closed-loop architecture (Click to engage)
If the data backbone is fragmented, every part of the loop suffers. Operators see partial truth. Cloud teams spend time reconstructing state instead of improving models. Every new use case starts with another bridge, adapter, or translation layer. That is why physical AI needs a data-oriented architecture.
Why App-centric Integration Breaks
Most teams start with applications. One team builds the robot stack. Another builds cloud analytics. Another builds dashboards. Another builds AI pipelines. Then someone has to connect them.
In conventional enterprise software, that may be inconvenient but survivable. In physical AI, it becomes a structural weakness because the system depends on timing, state, liveness, and trust under unreliable conditions.
Physical systems need more than payload exchange. They need shared understanding of what data means, how fresh it is, whether it is the latest state or only an event, what should happen when links degrade, and what a late-joining component must recover to become operational. They also need live observability. When a remote node goes dark, the team has to know whether the cause is network loss, stale state, schema drift, a Quality of Service (QoS) mismatch, or hardware failure.
This is where bridge-centric edge-to-cloud designs start to fray. Custom gateways, protocol translation, cloud adapters, and telemetry workarounds can be acceptable for narrow one-way export. However, they are much less acceptable when the system must support shared state, late joiners, selective data movement, live diagnosis, coordinated rollout, and continuous feedback into AI development.
At that point, the bridge is no longer a simple connector. It becomes a permanent integration tax. Change cost rises with every new consumer, every schema evolution, and every new operational question. The architecture quietly teaches the organization to rebuild the path every time it wants to learn from the system.
What a Data-Oriented Architecture Changes
A data-oriented architecture starts from a different assumption: the long-lived asset is not the application boundary, but the operational data layer shared across the system. Applications still matter, but they become replaceable participants in that layer instead of private owners of it.
The interface is therefore not just payload. It is data plus metadata plus behavioral rules. In practical terms, that means shared data models, explicit state semantics, timing and lineage, discoverability, and QoS rules that describe what must be reliable, what must be fresh, what may be filtered, and what must survive degraded links.
This is the important contrast. In an app-centric design, teams share data indirectly through APIs, gateways, and custom translations. In a data-oriented design, they share it directly through a common contract for state and communication behavior. That lowers coupling, makes late-joiners easier to support, improves observability, and reduces the cost of adding or replacing components.
The same operational data stream can then do several jobs at once. It can drive real-time behavior at the edge, give operators a live view of the system, feed simulation and model tuning, and support validation and staged rollout. That is why the phrase “data is compute” is useful here. In physical AI, the data path is doing part of the real systems work.
This matters now because physical AI turns edge and cloud into one loop: field behavior informs cloud analysis, which informs simulation, training, and new operational changes. If that loop runs on disconnected data paths, trust and portability degrade. But if it runs on one coherent backbone, the system becomes both easier to operate and easier to improve.
Fleet Diagnostics Show the Difference
Consider an automotive or robotics team rolling out a new capability across a fleet. Two days later, field reports suggest an intermittent fault under a specific combination of operating conditions. The team needs answers quickly.
Which units are affected right now? What is their current state, not just the last log they happened to upload? Can the team change what telemetry is sent to the cloud without rebuilding edge software? Can it coordinate a corrective rollout while keeping a trustworthy view of what is current, stale, or missing?
An app-centric architecture usually answers those questions by piling on more machinery: another gateway, another telemetry path, another cloud-side mapping, another custom query surface. Each addition may help locally, but it also deepens dependence on a translation layer that was never the real system of record.
Worse, each extra layer tends to distort the question being asked. Logs are delayed. Schemas differ between edge and cloud. One service thinks in events while another tries to reconstruct state from those events after the fact. Operations teams end up debating whether they are looking at a real system condition or an artifact of the integration path. That uncertainty is expensive when a rollout decision has to be made quickly.
A data-oriented architecture answers the same questions from a stronger starting point. The fleet already shares common data models, state semantics, and QoS behavior. Operators can identify the affected slice from live system state, not from a delayed reconstruction. Telemetry policies can be adjusted without redesigning the edge application model. Cloud services analyze the same operational facts that edge applications use, instead of a second, lossy representation derived after the fact.
This is where trustworthiness stops being a slogan and becomes an operational property. In physical AI, trust is not only about model quality. It is also about whether the system can expose its own state while it is running. When a node disappears, teams need to distinguish between transport failure, stale data, misconfiguration, and hardware problems. If the architecture hides that truth behind layers of glue, the system is operationally a black box. If the architecture makes state, liveness, and communication behavior first-class, operators get a much more inspectable system.
That inspectability matters beyond incident response. It also affects how confidently a team can run experiments, stage updates, and reason about rollback. If the system can show which nodes have received a change, which are temporarily disconnected, and which are running on stale assumptions, the organization can make more disciplined operational decisions. If it cannot, every rollout becomes partly an exercise in inference and hope.
The same backbone also strengthens the AI improvement loop. Real-world observations can move into simulation, validation, model tuning, and staged rollout with less manual wrangling and fewer blind spots. The important benefit is not only cheaper diagnosis. It is cheaper change. The system stops requiring a bridge redesign every time the organization wants to learn from the field.
Agentic Engineering Still Needs Real Data Contracts
This architectural choice also matters for AI-assisted development. Faster code generation does not remove integration complexity. In many organizations, it accelerates it. Teams can now produce wrappers, services, and glue more quickly than before. Without a stable operational data layer, that speed just creates integration sprawl faster.
Agents need durable interfaces too. If meaning lives only in local naming conventions, informal APIs, or half-documented adapters, agents will guess, and they will guess inconsistently. A semantic catalog, built on shared data models, topic meaning, ownership, and communication expectations, gives both humans and agents something firmer to build on. It also gives reviewable structure to AI-generated changes. Instead of asking whether generated code happens to work against one service version, teams can ask whether it conforms to the shared contract and operational expectations of the system. The winning pattern is not “let the agents invent the system.” It is “give humans and agents a trustworthy substrate to extend.”
What Technical Leaders Should Build First
If you are building a physical AI system today, your first architectural brick should not be another isolated application or another custom bridge. It should be the operational and semantic data backbone.
Start with the data contracts and operational semantics that must survive across edge and cloud: data model, state model, timing model, QoS model, and observability model. Make that layer discoverable, inspectable, and resilient under degraded links. Then let applications, dashboards, models, and agents plug into it.
That recommendation means choosing the shared layer that future decisions can build on. Once the system has a durable contract for data and behavior, teams can change applications, adopt new analytics tools, expand cloud workflows, or introduce more autonomy without renegotiating the whole integration story each time.
Technologies such as the RTI Connext databus matter because they provide a proven implementation of this pattern across distributed edge and cloud systems. But the broader point is architectural, not product-specific. Physical AI needs a shared data plane that is real-time, state-aware, observable, and portable.
Use a simple rule. Before adding more applications, agents, or bridges, define the data contracts and communication behavior that must hold across the system. That is the path to trustworthiness, interoperability, and continuous improvement. If those outcomes are currently hard to achieve, the data backbone is the likeliest place to start.
For more on this topic, don’t miss the other installments of our blog series on real-time data streaming.
About the author:
 A Distinguished Engineer at Real-Time Innovations (RTI), Dr. Rajive Joshi possesses deep expertise in software system architecture tailored for trustworthy autonomous systems. His professional focus encompasses sensor data fusion, robotics, distributed real-time embedded systems, and project leadership. Throughout his career, Dr. Joshi has made significant contributions to RTI’s Connext Databus and various open-source initiatives, while also securing multiple patents and is Chair of the Connectivity and Communication Subgroup at the Digital Twin Consortium.
A Distinguished Engineer at Real-Time Innovations (RTI), Dr. Rajive Joshi possesses deep expertise in software system architecture tailored for trustworthy autonomous systems. His professional focus encompasses sensor data fusion, robotics, distributed real-time embedded systems, and project leadership. Throughout his career, Dr. Joshi has made significant contributions to RTI’s Connext Databus and various open-source initiatives, while also securing multiple patents and is Chair of the Connectivity and Communication Subgroup at the Digital Twin Consortium.
Dr. Joshi earned a Ph.D. in Computer and Systems Engineering from Rensselaer Polytechnic Institute. He is also a recipient of the IEEE best paper award for his work on multisensor fusion. In addition to his technical reports, he has published numerous papers and a book focused on multisensor data fusion.